Hi – Julia here. Like Shira, I just spent the last week attending the Association of Moving Image Archivists (AMIA) conference in Savannah, Georgia. AMIA brings approximately 500 moving image professionals and students from all over the world for a wide variety of workshops, panels, and special screenings. While it’s too much to cover in depth, those of you unfamiliar with the conference can check out the program as well as another blog post by NDSR Boston resident Rebecca Fraimow.
As part of my conference experience, I chaired and moderated a panel on digital forensics applications with personal collections with speakers Elizabeth Roke, Digital Archivist at Emory University, and Peter Chan, Digital Archivist at Stanford University. The work of both directly correspond to my projects at NYU Libraries where I’ve been tasked with developing the infrastructure, policy, and workflows to preserve and make accessible born-digital collections. One of the major collections I”m working on are the Jeremy Blake papers and his “time-based paintings.” I’ll detail my progress in this area in my next post.
This panel was the first of its kind to be introduced to the AMIA community. There had been no previous discussion on digital forensics concepts, use cases, or projects, making this panel a unique experience as both a moderator and a community member. Digital forensics has its origins in the legal and criminal investigative worlds, but its support of archival principles such as provenance, chain-of-custody, and authenticity, have driven its recent adoption in the archives.
While digital forensics is an emerging field, both Emory and Stanford were among the first universities to create forensics labs and equipment to process backlogged obsolete born-digital media. Much rarer, both Emory and Stanford do not stop at ingest. They’ve both processed collections now accessible to researchers.
Elizabeth Roke, Emory University
Elizabeth Roke began her presentation with an introduction to digital forensics concepts and workflows. She strongly emphasized, however, that there is a huge gap between ideal workflows and the reality of born-digital processing. This is a theme that was returned to throughout the panel and Q&A. She often, for example, finds herself processing media with little to no documentation. File names can be baffling and nondescript (“ ,,,,,,.doc”). Chain of custody may already be broken by well-meaning individuals who have copied files over, permanently altering their time stamps. Additionally, Elizabeth stressed that disk imaging itself–the initial process of refreshing the media into a more actionable format–could take a lot of time, effort, and experimentation, and was not always successful.
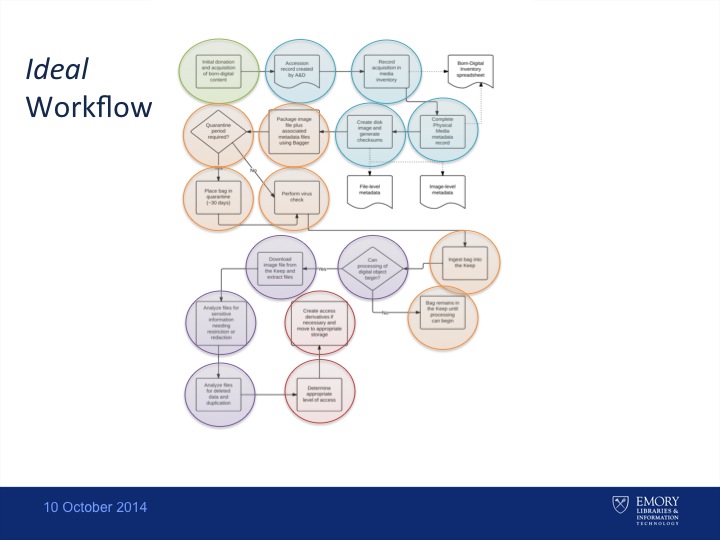
Elizabeth also updated us on Emory’s seminal work on Salman Rushdie’s 4 personal computers, as well as some of the recently processed, less complicated collections, such as the Alice Walker papers. Preserving and providing access to the Rushdie computers involved significant dedicated staff time because of both the high level of technical requirements involved in full-scale personal computing emulation, and because of the number of nuanced access levels and restrictions. Few institutions can dedicate the resources to make such a project happen. While the earliest Rushdie computer was emulated and accessible in February 2010, the remainder of the Rushdie born-digital collections is not yet accessible. She contrasted that immense project with The Alice Walker papers, a collection of word processing files on floppy disks with comparatively few restrictions.
Peter Chan, Stanford University
Peter Chan then jumped in via skype to discuss and demo ePADD (email: Process, Accession, Discovery), a Stanford project specifically tackling email processing that is scheduled for an April 2015 release to the public (NYU Libraries is a beta-tester on this project). One of the great things about ePADD is that it easily addresses a major stumbling blocks in born-digital access: personal and private information extraction. ePADD extracts text for key word searches to cull sensitive content such as those based on health, social security numbers, credit card numbers, and any other topics deemed private by a donor. While you can read much more about ePADD in a recent post, one of the fun aspects are the visualizations possible through ePADD. ePADD mines email records and can create cool visualizations displaying words usages and corresponandances over time, as seen below with the Robert Creeley papers image (courtesy of Peter):
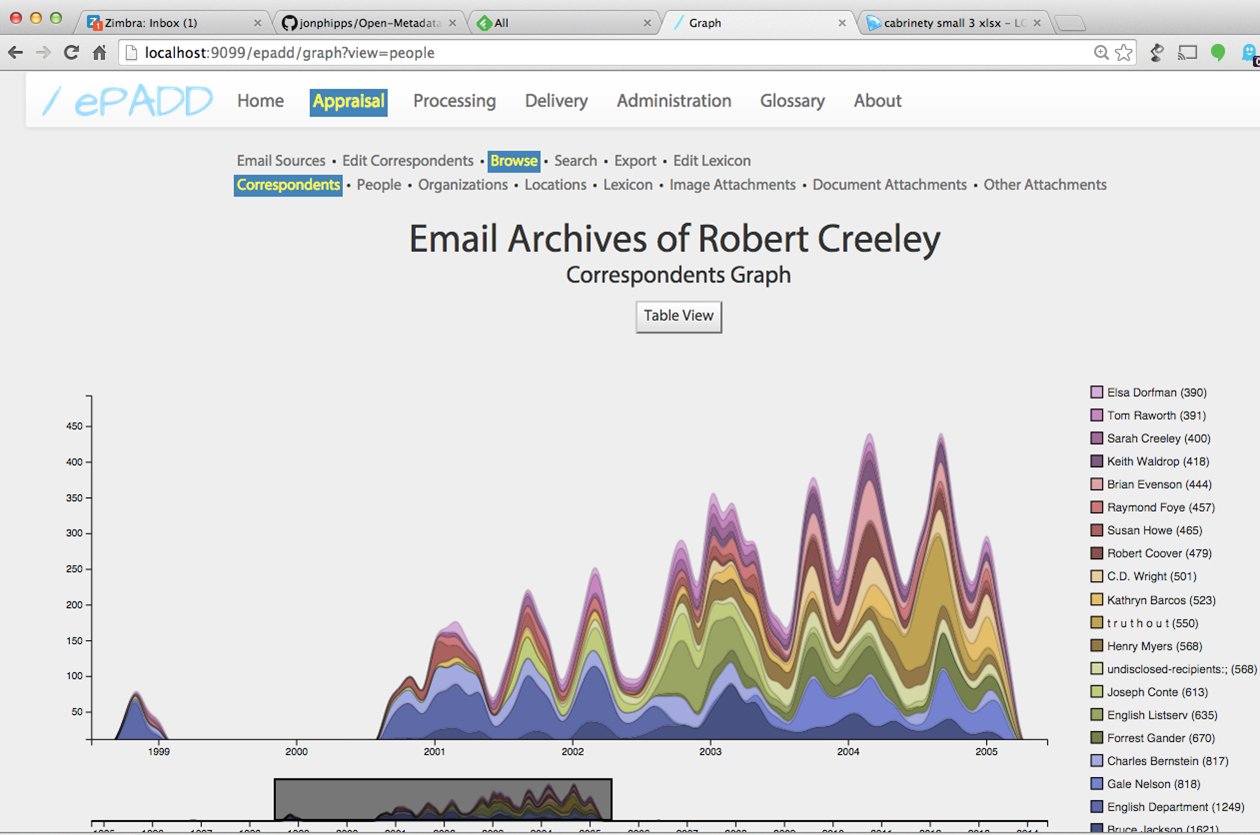
“The Roke and Chan virus gap”
At the end of the panel, audience members asked some interesting questions highlighting different institutional responses. For example, how do each of the institutions handle viruses? Are they worth preserving despite the risks? Stanford preserves the whole image, virus and all. Emory excludes viruses from ingest. Emory, it turns out, also preserves the disk image with viruses, but excludes viruses from any exported files. Some institutions may exclude viruses from ingest. This is only one example of differences in not only methods, but values and evaluations determining what are objects of study for future researchers. One person’s context is another person’s text. At this point, we can all only speculate; the researchers aren’t there.
While my task is to develop policies addressing issues like this, I’m not sure what we’ll be doing in this area! In my preliminary surveys, I can already tell that preserving and making accessible Jeremy Blake’s work, for example, will present for a whole other set of considerations due to its artistic context. Determining the essential qualities will present challenges that a text-based record, for example, wouldn’t. I’ll blog more about that in my next post!