
cowsay, possibly the most important thing I’ve learned in my residency.
In this post, I’ll talk about micro-services, and the archival workflow at CUNY Television. I’ll also talk about the work I’ve done to modify and document the micro-services, and my impressions about working with code thus far.
What are microservices?
Before delving into how CUNY Television implements micro-services in our workflow, it is probably best to first explain the term generally, and then provide some examples of how I’ll use it. Micro-services are both a framework that is applied in the context of software development and architecture, as well as a set of scripts that accomplish specific tasks.
Micro-services break down extensive, multi-step processes inherent in digital preservation workflows into distinct pieces. Micro-services also provide freedom from the constraints of monolith software architecture, which imposes a workflow and process on the user. Compared side by side, “a monolithic app is One Big Program with many responsibilities,” whereas “microservice-based apps are composed of several small programs, each with a single responsibility.” [1] This approach gives the archivist better understanding and control of a digital object’s preservation life-cycle. This framework also provides freedom from the constraints of monolith software architecture, which imposes a workflow and process on the user.
Using a micro-services approach in the context of digital preservation may require some technical knowledge and willingness to “peek under the hood,” which can be a barrier to use and adoption for some. A helpful resource is The California Digital Library micro-services PowerPoint slides, which gives a good overview of their approach to digital curation. Overall, the CDL has found that micro-service “increases the flexibility of the environment, its ability to exploit changing technologies, and enables it to develop sufficient complexity to deal with evolving demands without becoming baroque.” [2]
Micro-services at CUNY
CUNY Television uses approximately thirty micro-services, each of which accomplishes a specific task or set of tasks. For example, makeyoutube is a micro-service that creates an h264 file that is suitable for uploading to YouTube, and makelossless losslessly transcodes a video file (with options for ffv1 or jpeg2000), creates md5 checksums, and creates metadata using mediainfo. The micro-service makemetadata uses ffprobe, mediainfo, and exiftool to create metadata reports for video files. If you’d like to see a list of all CUNY Television’s micro-services, which are written in the language bash and run as commands in the terminal application, check out the project’s GitHub repository. I’ll be updating this area as the project progresses, with documentation that outlines how to install, configure, and use the micro-services. Our hope is that other institutions might find them helpful, and that people will submit enhancement suggestions via the issue tracker, or better yet, experiment with modifying the code themselves.
In terms of my residency, My work with the micro-services has been to interview staff and make recommendations for improvement of the scripts, log these suggestions via an issue tracker on GitHub, make changes to and test new versions of the scripts, and create documentation for the implementation and use of micro-services by others. So far, I’ve interviewed library and archive staff, as well as operators in the control room. For the most part, the changes suggested are small tweaks that smooth out a workflow, automate a task that was previously done by hand, or add more metadata about the processing of digital files. As of this week, I’ve added the following changes:
- preservation and PSA modes to ingestfile, which allow for public service announcements and files from digitized AV assets to be packaged using it
- standardized variables and functions across all of the micro-services scripts
- created a script to transcode files for ingest into our digital asset management system.
CUNY Television workflows
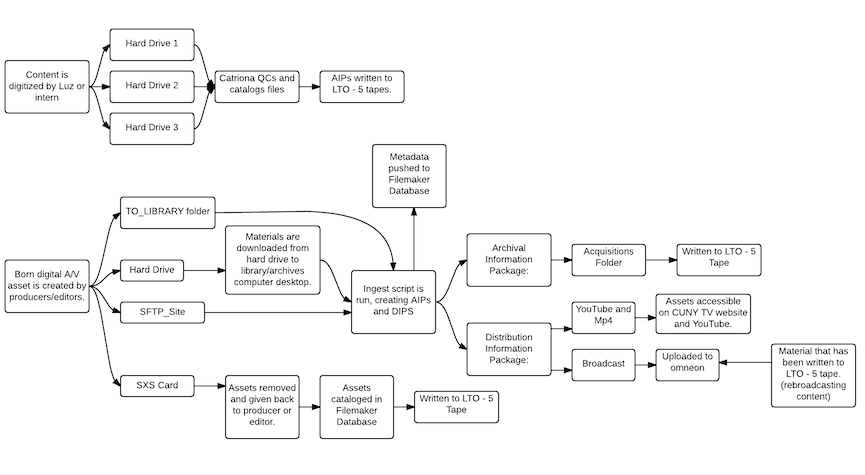 (I created this workflow diagram using Lucidchart)
(I created this workflow diagram using Lucidchart)
The CUNY Television Library and Archives are centrally located within the broadcast station’s overall workflow. Before a program can go to air, it must be processed through the library. Producers transfer their content to us via file-transfer, hard drive drop-off, or deposit into a networked folder. Once we have the final edited version for air, we run a micro-service script called ingestfile. Oksana Israilova, the broadcast librarian, is the primary person who runs file ingests. She types ingestfile -e into the terminal, which opens a GUI where she inputs the unique media ID, and selects any changes to the audio and cropping. The script takes the file and transcodes copies for access, creates metadata for each copy, and delivers access copies to the omneon server (which runs the broadcast), and to the web team for upload to Youtube. ingestfile also packages all of these items up into a nice, Archival Information Package:
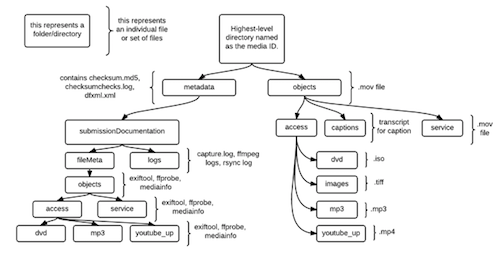
(I created this diagram using Lucidchart)
Eventually, these packages get written to LTO tapes, which are our primary means of offline storage. ingestfile offers a queue function, so Oksana waits until she has multiple files to run this process. Another functionality of ingestfile is that it creates an mp3 file that gets uploaded to our transcription service, Pop Up Archive. Pop Up Archive returns a transcript which is then edited and used to create closed captioning for select broadcast shows.
Simultaneously, we are also digitizing tapes. CUNY Television began broadcasting in 1985, so there’s plenty of historical content housed on U-matic, Betacam, and Betacam SX tapes. Digitization is seen as part of the regular day-to-day operations at CUNY Television, as opposed to a one-time or grant funded process. Digitization is conducted by interns and CUNY Television staff member, Luz Reyes. Currently, we have a 3:1 workflow, which means that Luz is typically digitizing three tapes at once. Between Luz and an intern, CUNY Television digitizes approximately 18 hours worth of content each day, totaling 90 hours (just short of 1 terabyte) per week! We use the open source software vrecord to conduct digitization, and Catriona Schlosser, the assistant archivist, conducts quality control using QCTools. Following quality control, digitized files are packaged using the same ingestfile script, but with an added -p (for preservation mode). In preservation mode, the user inputs the in and out times, and drags in the metadata logs created during digitization, but the file is not delivered for broadcast or upload to YouTube. Instead, the AIP is housed in the same directory as the input file originated from.
Finally, the library also handles raw, remote, and b-roll footage from producers. We don’t yet have a standardized process for this, but it is something I’m going to be working on down the line. Producers bring in footage from shoots off-site on hard drives or xdcam drives, and Catriona transfers the material to a computer and catalogs it in our database. This type of footage presents a problem for our ingest script, as it comes to the archive as a specific directory structure, chosen by the producer, unlike individual shows, which just arrive as files. Ideally, we’d like to create a specification for ingestfile (like -p for preservation mode) that can handle a directory input, and that would somehow maintain the original directory structure specified by the producer but have the contents of an AIP. Currently, these files get written to LTO tape for long term storage.
Making changes to the code, or how I broke everything and had some feelings about it
For me, documenting workflows, interviewing CUNY Television staff about their ideas for micro-services improvements, and making modifications to the micro-services code has been really fun and informative. But, I feel like it would be disingenuous for me to say that it has been smooth sailing, or that I haven’t left work some days feeling defeated by bash, the language we use for our micro-services. The thing I’m learning about working with code is that it isn’t personal- sure, your script fails because you typed something wrong, but these mistakes don’t mean that you’re “bad” or “unsuccessful” at coding. In fact, this failure is integral to the learning process. Every time the code fails, I learn something new about the functionality and rules of the language. I have to constantly remind myself that making mistakes is all part of the process, and that there wouldn’t be a point to the residency if I knew how to properly implement all of the changes to our code. While I still get frustrated by mistakes I make, I look forward to learning more as the residency continues.
Looking Forward
As my residency continues, I’ll make further edits to the micro-services and create documentation. Determining a way to ingest raw footage and b-roll using ingestfile, creating an Archival Information Package Validator script, and developing scripts for our data migration are all micro-service enhancements that I’ll be undertaking over the course of my residency. I’m particularly excited and hopeful that creating documentation will lead to adoption and development of the micro-services by individuals from outside of CUNY Television. Our objective in doing all of this is to participate within a larger discussion about, and support the development of, open source software for archiving and preserving audio visual assets. Audio visual archiving can be an expensive endeavor, but there are ways to make it more affordable through useful and easily adoptable workflows and software.
UPDATE: Click here to view my poster as a PDF!
[1] “Why microservices matter” Heroku Blog. https://blog.heroku.com/archives/2015/1/20/why_microservices_matter
[2] JISC Digital Infrastructure Team. http://infteam.jiscinvolve.org/wp/2010/12/08/micro-services/comment-page-1/