
In January, my NDSR-NYC host site, Rhizome, announced that the organization had received a two-year grant from the Andrew W. Mellon Foundation to fund the comprehensive technical development of Webrecorder, “a human-centered archival tool to create high-fidelity, interactive, contextual archives of social media and other dynamic content, such as embedded video and complex javascript,” which Rhizome is building in partnership with San Francisco-based programmer Ilya Kreymer.
Kreymer defines “high-fidelity” web archiving as the process of capturing dynamically generated content through the web browser, instead of copying a website as static files. “Everything that is loading in the browser is both recorded and played back, so that nothing is missed,” Kreymer explains. “If there’s some complex resource that is loading, we’re able to record it and to play it back.”
The browser-based recording process is central to Webrecorder’s “human-centered” approach, from both a technical and a conceptual perspective. From the technical perspective, shifting the location of web archiving to the browser provides a natural capture point for recording specific outcomes of client-side actions that are executed as a user interacts with a website. Web archiving through the browser provides the ability to capture many varieties of highly individualized and perishable web content, such as social media feeds, which present a unique experience to each user at any moment in time. From a conceptual perspective, locating the capture process within the browser demonstrates the inextricability of user participation from the generation of content within dynamic websites. Since user interaction, mediated by the interpretive and generative capabilities of browser software, is an integral component of dynamic content, enabling user participation in the recording process can deliver a fuller representation of the experience of a site to be preserved.
Webrecorder, with its goal to build accessible web archiving tools and place them directly in the hands of individuals and communities, fits within Rhizome’s broader mission to support the creation, dissemination, and preservation of “richer and more critical digital cultures”. Through this project, Rhizome and Kreymer hope to contribute to the diversification and strengthening of “digital social memory,” as explored in a recent panel discussion offered by Rhizome at the New Museum.
During Kreymer’s recent visit to Rhizome’s office in NYC, I asked him about how Webrecorder’s emphasis on user experience and participation differs from traditional web archiving approaches, and how this unique perspective is shaping his development of the tool at the start of the two-year project.
MM: What is “symmetrical web archiving”, and how does this relate to Webrecorder as a tool for supporting “human-centered” web archiving?
IK: Symmetrical web archiving is a new approach, and perhaps unique to Webrecorder, that essentially uses the same technology to archive and replay the same content. More specifically, in order to capture the content of a website, in this process the user is browsing and interacting with the website exactly as they would in their normal use of the site, and when playing it back, it’s essentially the same interaction, and so the same software is used to record and to play back the site.
On a technical level, how this works is that in the re-writing system that Webrecorder uses, the page corresponding to a particular URL is re-written such that it goes through Webrecorder, and the prefix that is added to it, is Webrecorder.io/record, and that causes a particular page to be recorded. And then to play it back, the same infrastructure and the same code is used, except that we switch to Webrecorder.io/replay prefix, and that allows for it to work exactly the same way, as far as the user is concerned, and the browser is concerned, but on the back end, Webrecorder is loading the page from an archive source–from a WARC file, rather than loading the live site.
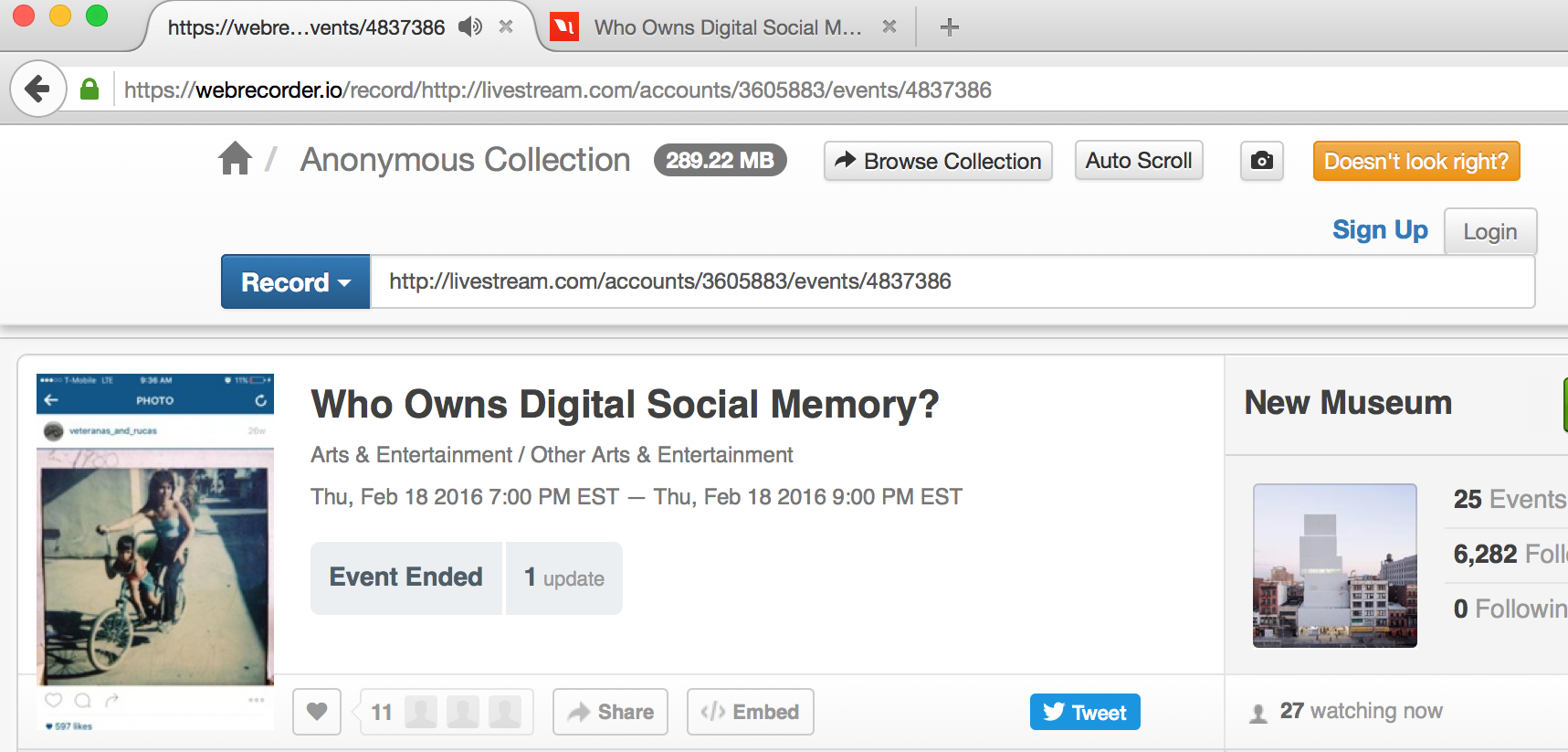
In Record mode, the page for a URL is re-written through Webrecorder, as indicated by the “record” prefix added in front of the page URL in the browser address bar. The “Record” button stays visible during the capture process, providing a visual indicator that allows the user to see what content is being added to a collection.
This approach is really different from how web archiving has been done traditionally, where there was a crawler, or some other tool–not a user, but a machine, essentially–that would go and grab certain parts of a website. While that may have been faster, that approach is often very incomplete, because the crawler doesn’t browse a site the way a user would. It makes decisions based on certain heuristics, and often times it doesn’t run javascript, and even if it does, it follows a specific pattern, and can’t use the site the way an actual user would. And so, the archive of the site is often incomplete, and different than how an actual user would use the site.
For example, if a site includes some kind of custom scrolling, or a custom interaction that requires a user to hover or to click somewhere, an automated crawler would most likely miss that, because a crawler if unable to do that. But if an actual user performs these behaviours when recording, when playing back the site, they perform the same behaviours, or even–not necessarily in the same order, but some of the same interactions–then they should expect that the content generated by those interactions can be replayed. That’s what is meant by symmetrical web archiving.

In the current version of the Webrecorder interface, a drop-down menu allows the user to switch between Preview, Record, Patch-record, or Replay modes.
MM: Could you say more about how javascript prevents traditional crawlers from capturing the complete content of a website?
IK: When a crawler sees a static HTML, it doesn’t necessarily execute javascript commands that a browser would. Traditionally, most crawlers do not (such as the Heritrix crawler, which is used by most large web archiving organizations as well as smaller tools like wget and wpull) are designed to fetch a certain number of resources, and discover more resources on a page, and they do that by analyzing an HTML page and extracting other URLs from that page. But with dynamic sites, what happens is that all the URLs that are available are not just a list of links on a page, but they are created dynamically, they’re generated on the fly.
So for example, if a user is interacting with a page in a way that changes the page, such as if a user is playing a game that requires a fixed set of moves, a crawler would just look at that page and see an empty board. But if a user loads a page, and let’s say they’re playing tic-tac-toe against the computer, they play a game in a specific way, and a browser will then render certain pieces in certain locations, in response to the user. And then, when playing back that page, it’s possible to play back that exact game. And the user can do that many times and archive that specific — we’re not archiving the game itself, we’re archiving that particular game, or that particular playing of the game: that series of moves. But a crawler, without the user, would not know how to play the game, unless someone writes a specific script, that’s designed for that specific site…it would be a very involved process to do that. But with a browser, it’s very easy, because the user just interacts with the page in the way they would normally.
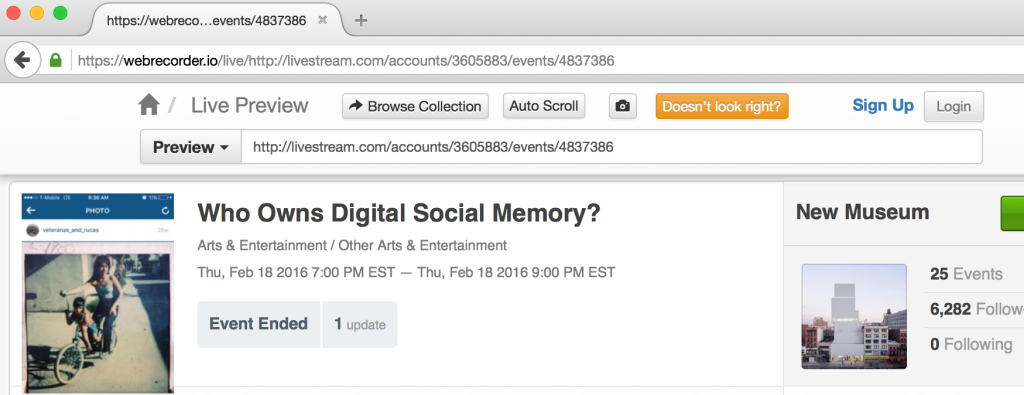
Browsing a site in “Preview” mode through the Webrecorder interface allows for a user to explore a site, evaluate the content, and determine what to capture, while the recording is “paused”.
MM: Even though crawlers copy all the javascript, and the WARC file will have the javascript, it doesn’t have the URLs, because those never get formed.
IK: Right. So you could then read that javascript in a browser, and then execute it, and then fetch more URLs; so you would be able to “patch”– to improve the previous crawl– through the browser, but without having a browser, the chances of accurately capturing a page is much lower, because web pages were designed to be viewed in a browser. So a tool that’s different than a browser, that’s trying to make a representation of that page, is always going to be incomplete. That’s another way to look at it, perhaps.
I could add one more point. With “human-centered” web archiving, Webrecorder adds another dimension, which is that is that we allow users to log in to sites, in the way that they normally would, and without recording, and so for example, a user can log in to Twitter, and archive their specific Twitter feed at that particular moment in time.
In the browser, this would just appear as twitter.com, but it would be that particular user’s view of twitter.com, at that particular moment in time. And so this allows users to create extremely personalized archives, and this is especially true of social media, in that one user’s twitter.com, or fb.com, looks completely different than another user’s, because there is personalized information that is presented for that user once they log in.
Traditional web archiving tools do not provide any way to capture this– if you look at twitter.com or fb.com in the internet archive wayback machine, you’ll see the generic twitter.com or fb.com interface. And that totally makes sense, because that’s a public web archive that is presented to the general public. But with Webrecorder, we really want to allow users to create their own personalized web archives, so they can create their own collections. Each user can archive their own twitter stream, and keep it private to themselves, or they can choose to share it with the world, and that’s up to that particular user, to decide how they want to curate their personal web archive, and also how much of that archive to create. For example, going back to twitter.com, a user could just archive the first page, or they could choose to scroll down to the beginning of their feed, or choose where to stop, and it’s entirely up to the user, to decide how little or how much they want to archive, as opposed to an automated crawler, that has to make that decision based on some pre-set rules. So it’s entirely up to the user, to set the boundaries of their archive.
Even twarc doesn’t give you a web archive. It uses a twitter API, so the approach is fundamentally different in that you have to follow the twitter API, and you have to be registered with that, and it’s the information that twitter gives you through that API, versus what you get by loading twitter through your browser. With our approach, the focus in high-fidelity web archiving is that “what you see in the browser is what you archive.”
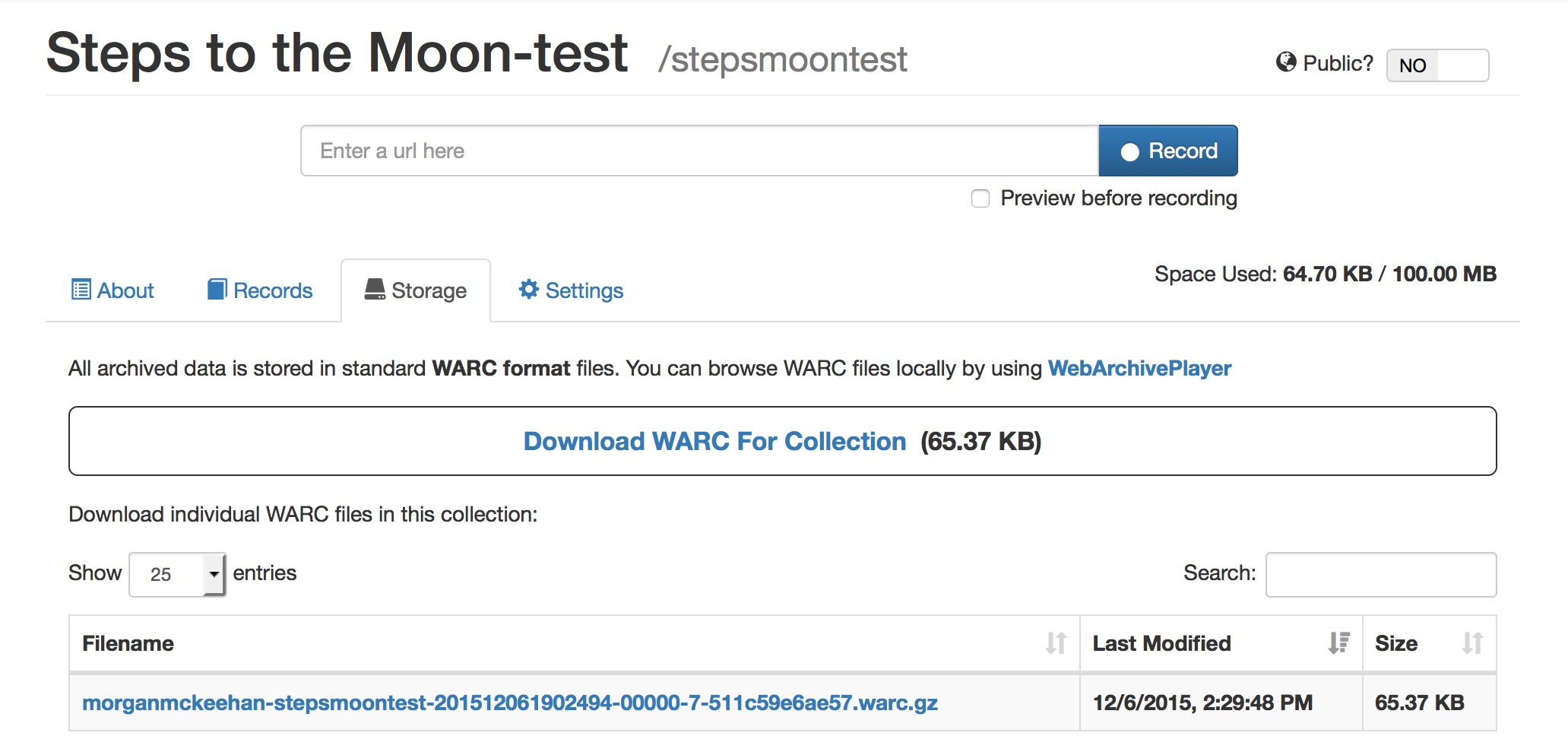
From a user’s account in Webrecorder, all of the records for each collection can be viewed and downloaded as a WARC to be stored locally and replayed via WebArchivePlayer, a free and open-source viewer for WARC files which Kreymer has also created.
MM: What features are you working on for metadata, for the collections users create with Webrecorder?
IK: Right now Webrecorder provides basic recording and replay: we capture the page at high-fidelity, and we’re able to play it back at high-fidelity. And the other question, is: how do users find out what they’ve archived, and how do users make sense of their archive? Say they’ve recorded 100 pages. What’s next? Those are some of the difficult questions that we’ll be tackling in the near future, with this project.
In addition to just capturing the page, or a particular user interaction, there’s also a fair amount of metadata that’s automatically captured in our approach, that isn’t necessarily available for users in other approaches. Some of these include, for example, what browser a user is using, because the browser sends that information to the http server. We also know what page was viewed, and which pages were visited from what other pages, so we can create a link-graph of exactly the way that a user visited their archive, so we can trace back and create a history, or not just what page was visited on what date, but what resources were loaded from which page, and how the user navigated through a site.
Another option would be to index the text into an open source search engine, such as Solr or Elasticsearch, and allow users to search the content of their archives. Since we know what content they’ve archived, we could also allow users to search by images, or specific resource types, for example if a user wanted to archive 100 pages, and then they wanted to find all the videos that they’ve archived, we should be able to provide a way for users to find that information, and to surface that to the user in ways that makes it easy for users to work with the archive.
In addition to automated metadata that’s available from the recording process itself, we’re also considering user-created metadata, such as allowing users to label specific pages in their collection, to be able to search by those. Another idea is page-level annotations, so that users can select text or any part of a page, and create an annotation, and for this there are excellent open-source tools like hypothes.is that we could use, that provide a framework for adding annotations to any website. We’re looking at this and considering ways to integrate annotations with web archives; that’s certainly a natural combination, because in order to have annotations, you need to have an archive, to make sure that the base material is preserved, and once you have the base material, it certainly makes sense to annotate it, in order to provide context for how the archive was created. So that is definitely something that we are exploring, as well.