Hello readers! I’m excited to inaugurate this cohort’s blogging with a post about my first few weeks in the residency. My host institution is CUNY Television, a public broadcasting station located at the City University of New York’s Graduate Center. My project at CUNY Television will be focused on assessing, improving, and documenting CUNY Television’s micro-services workflow, preparing for data migration from LTO-5 to LTO-7 tapes, and helping implement an internal Digital Asset Management system (here’s my project proposal if you’re interested). I’m working primarily with my mentors Dave Rice and Catriona Schlosser, but my projects will end up involving the whole broadcast station. In order to prepare for the technical nature of my projects, I’ve spent the first few weeks getting up to speed with the command line, introducing myself to the bash scripting language, and understanding the roles and responsibilities of the archives and library department, as well as the rest of the broadcast station.
In this post, I’ll go over resources I used to familiarize myself with bash and the command line, and a fun little project that I worked on, which helped me get comfortable with making changes to codec specifications in open source software that CUNY Television uses. Some of the concepts discussed in this blog post will be geared towards the A/V community, and while my hope is that I can explain them clearly, please feel free to ask any questions in the comments!
Bash, the command line, and CUNY-TV’s workflows
All of the micro-services in use at CUNY Television are written in bash, so it is a good idea for me to familiarize myself with the language, so that I can begin to make edits to our workflow. Starting to learn a scripting language can feel like a daunting task. I’ve had a little bit of experience with learning different languages, specifically python, during graduate school but without a day-to-day application, many of my skills fell by the wayside. After a week of tutorials and reading through the scripts themselves, I have a better understanding of how the language works, what it is capable of, and how I might begin to write useful scripts of my own. I also submitted my first pull requests on GitHub, which was exciting at first, but will hopefully become routine as my technical abilities grow. One of my project goals is to migrate the scripts to an institutional GitHub account, and provide documentation for their use.
If you’re curious about the resources I used, I took an online course via lynda.com, as well as using the bash reference manual, and the site learn x in y minutes. To brush up on the command line, I also completed a class via lynda.com, and the short code academy course.
Learning about the daily operations of the library and archive, as well as the broadcast station as a whole, is an ongoing process. As I’m moving forward with my project, one of the first things I’m working on is mapping out the workflow of assets once they enter the library and archives, so I’m spending much of the next few weeks learning the intricacies of everyone’s roles and positions, and the ins and outs of the micro-services that we use to process audio-visual assets. I hope to be able to share the results of that work, and talk more about that aspect of my project, in an upcoming blog post.
slices, slicecrc, and FFv1
As I mentioned earlier, I was also able to work on a fun project that was somewhat outside of the scope of my project proposal, but proved to be a great learning experience.
At CUNY TV, we use the open source software ffmpeg to transcode our audio visual materials, with the lossless FFv1.3 codec. For this project, I tested two different encoding parameters of the FFv1.3: slices and slicecrc. Slices is a function that allows for a frame to be split into a specified number of slices, and when slicecrc is enabled, “adds CRC information to each slide,” making it possible to conceal errors on a damaged slice by using the same slice from the previous frame. CRC stands for “cyclic redundancy check, and is an error detection code used to detect accidental changes to raw data.” This is a fairly useful function, but specifying slices can increase the file size, and modify processing time.
I was testing for two things: to see whether or not specifying slices and enabling slicecrc makes a significant difference in processing times or the resilience of the resulting files for long-term storage, and whether or not slicecrc worked as intended. To do this, I worked with Dave to create a test script that would encode a test asset (I used this one) with every possible slice option (4, 6, 9, 12, 16, 24, 30) and slicecrc enabled and disabled. Then, I intentionally created errors using a program called zzuf. The script also kept track of the size of the asset, and the processing time, so that I could see if there was a considerable difference between 9 slices and 24 slices, for example.

Here’s the short script used to create the test assets.
When I opened up the finished assets in QC Tools, using the temporal difference filter, I was able to assess whether or not slicecrc was actually working. After viewing all of my test assets, I found that while slicecrc worked as intended in a few cases, overall, it was clear that there was some issue that needed to be resolved with slicecrc.
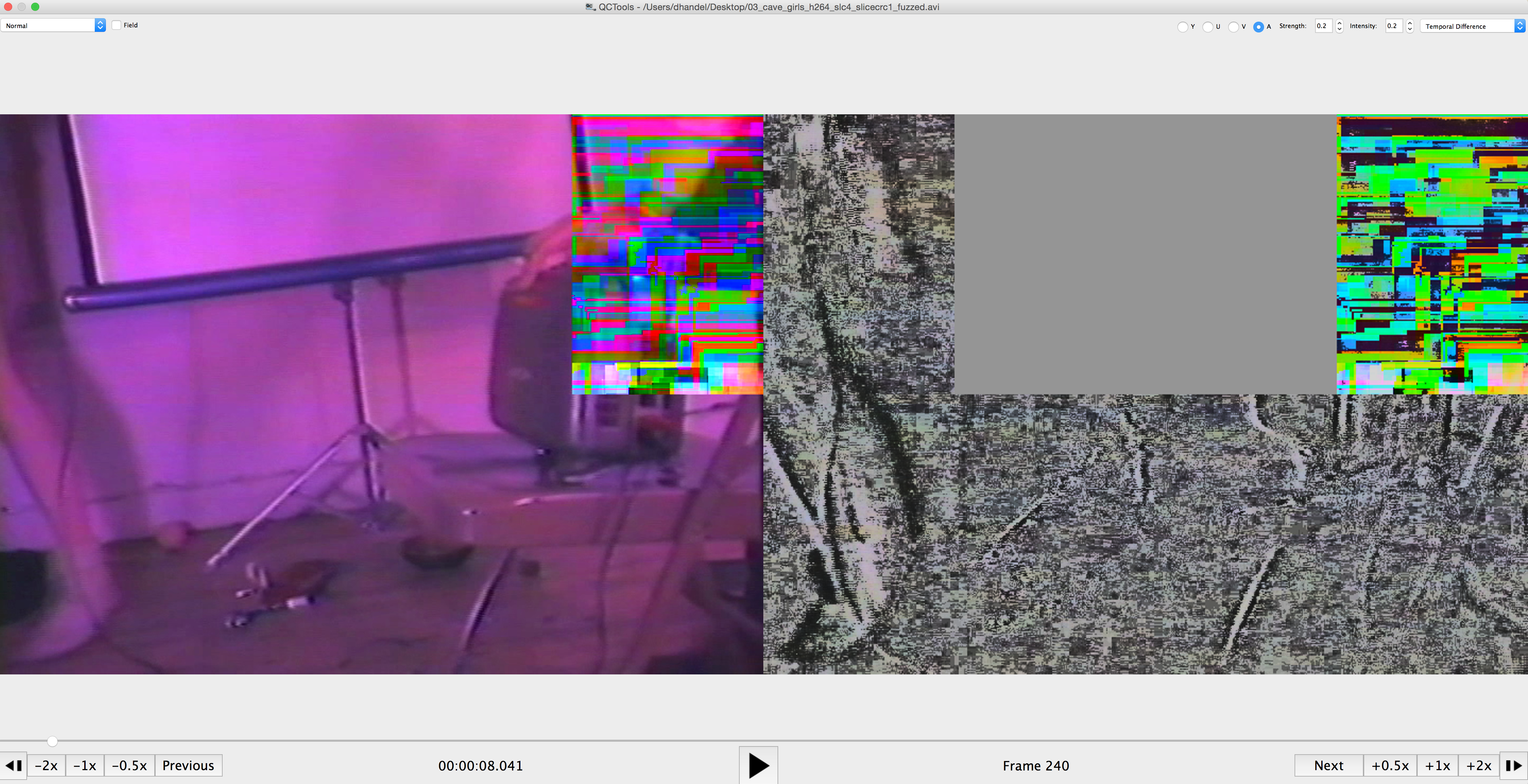
Here’s an example of slicecrc in which it is enabled but not working as intended. As you can see, the top right corner is still showing an error.

Here’s an example of slicecrc working as intended when enabled. If you look closely, you can see the top left corner is using an image from the previous frame.
Because this is open source software, ffmpeg offers the ability to report bugs via their wiki and listserv. I was a little nervous at first to tell a listserv, some of whom are developers, about the error I had found. But, I drafted a clear email, and to give me a little confidence sending it in, I had Dave look it over. The day after it was sent out, I received confirmation from the primary developer that the error was supposedly resolved! Excitement! I updated my version of ffmpeg and reran my tests, with success. With slicecrc enabled, the intentional errors I had made in the file were covered by the slice from the previous frame. The last part of the project involved updating vrecord on GitHub, so that the FFv1 specification included the best slice count (16, determined by file size and processing time) and slicecrc was always enabled.
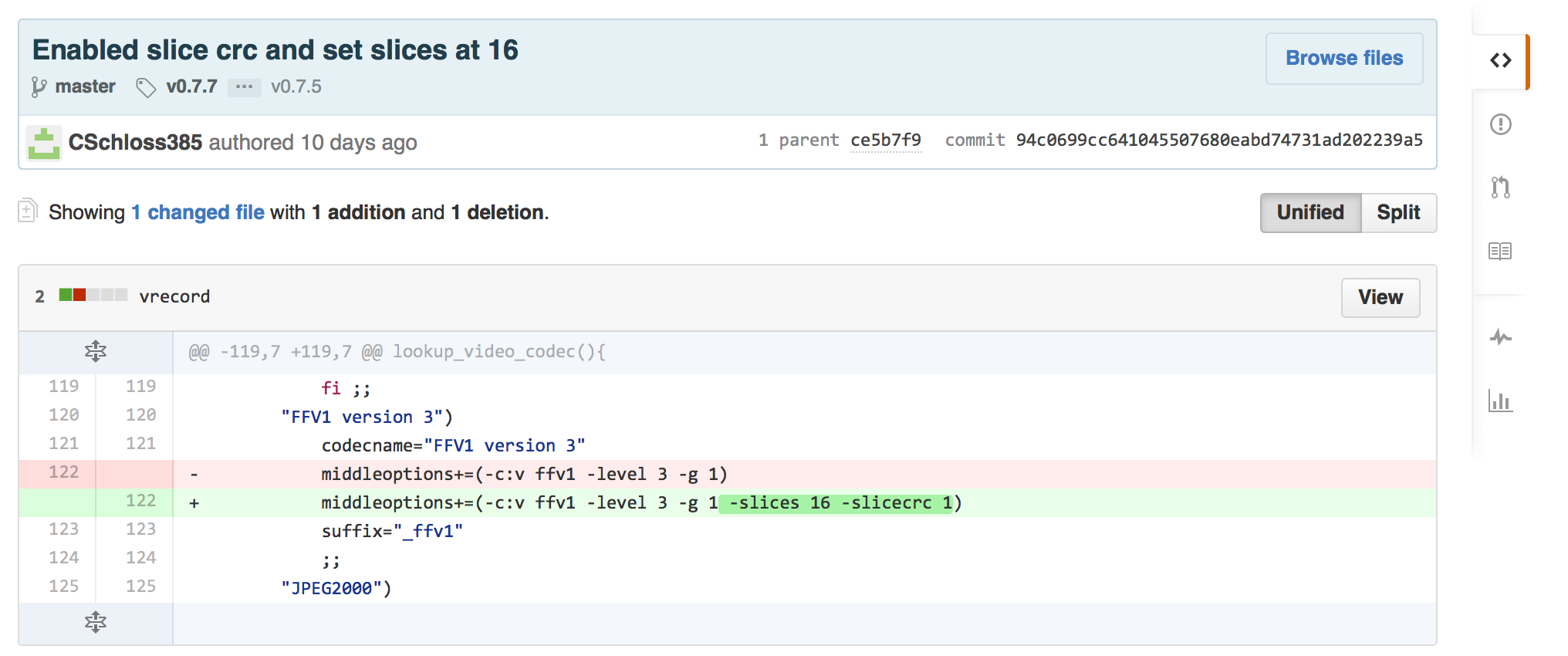
Here’s the GitHub history of the FFv1 specification changes that we made in vrecord.
All of this was very exciting to me, as it was my second week and I already was making (very) minor improvements to open source software. In addition to being exciting, though, it was also nerve-wracking, as I feel like I’m still very much in the early processes of learning, and so to assert an opinion or share findings on anything felt premature. However, because of the short duration of our residencies, there really isn’t time to proceed with trepidation. To return to the title of this blog post, I realized that the best attitude to have is to be unafraid and just dive in, head first. I’m only going to have to continue sharing my results, findings, and suggesting changes, so it is better to get any sort of insecurities or impostor syndrome out of the way early. I’m excited to continue contributing to a larger community of practitioners and developers, and to learn how to conduct research that benefits the development of open source software for audio visual processing.