Hello! I feel like so much has happened since I last wrote, and I’m excited to share some new project work with you all. I’ve been really busy at CUNY Television, continuing work on modifying micro-services and creating documentation for micro-services use. I still have a few more enhancements to complete before moving on to the next phase of my project- migrating a petabyte of data from LTO 5 to LTO 7 tapes. However, a lot of the work that I am doing now is going to assist with this migration, as it has to do with standardizing the structure and contents of our Archival Information Packages (AIPs) and writing scripts that automate file fixity, account for any changes to files, and ensure that our AIPs contain their necessary components.
With this blog post, I hope to start a discussion exploring how different institutions handle the creation, documentation, and migration of AIPs over time, as well as internal standards outlining the contents of AIPs. I will begin with a discussion of the AIP conceptual model, as outlined in the OAIS Reference Model, and then use my work at CUNY Television as a use case in how to document and verify the contents of an AIP. My observations at CUNY have raised large questions for me about how AIPs are approached by different institutions with many kinds of systems, and what kinds of tools could be used to document and verify the structure and contents of AIPs. To be clear, I don’t mean to suggest a standard that AIPs should adhere to- there is a reason the AIP model is conceptual. Instead, I’m curious to hear how others have handled documenting and verifying the contents of AIPs across varying institutional contexts. I hope you’ll contribute your ideas, in the comments, on twitter, or via email!
OAIS Reference Model and AIPs at CUNY Television
At CUNY Television, we follow a workflow that is akin to the OAIS Functional Model, meaning that we receive Submission Information Packages (SIPs) in the form of shows ready for broadcast and we transform those SIPs into AIPs and Dissemination Information Packages (DIPs). Our SIPs are the media itself, usually a ProRes file but sometimes files from SxS cards, hard drives, or tapes, and the associated metadata, which comes as an email from the producer describing the show, or is created by our Broadcast Librarian, Oksana. SIPs become AIPs through our ingestfile micro-service, which takes the SIP file and transcodes access and service copies, makes metadata, delivers access copies, and packages everything up into a directory named with a unique identifier. While most of our DIPs get delivered to the webteam and the broadcast server automatically in the process of AIP creation, we regularly return to our AIPs for files that need to be rebroadcast, meaning that in some cases, we have “active AIPs” which don’t really exist in the OAIS documentation, but are a legitimate concept in our workflow. [1]
For those of you who have not had the opportunity to read through the Reference Model for an Open Archival Information System (OAIS), an AIP is defined “to provide a concise way of referring to a set of information that has, in principle, all the qualities needed for permanent, or indefinite, Long Term Preservation of a designated Information Object.” (4-36)
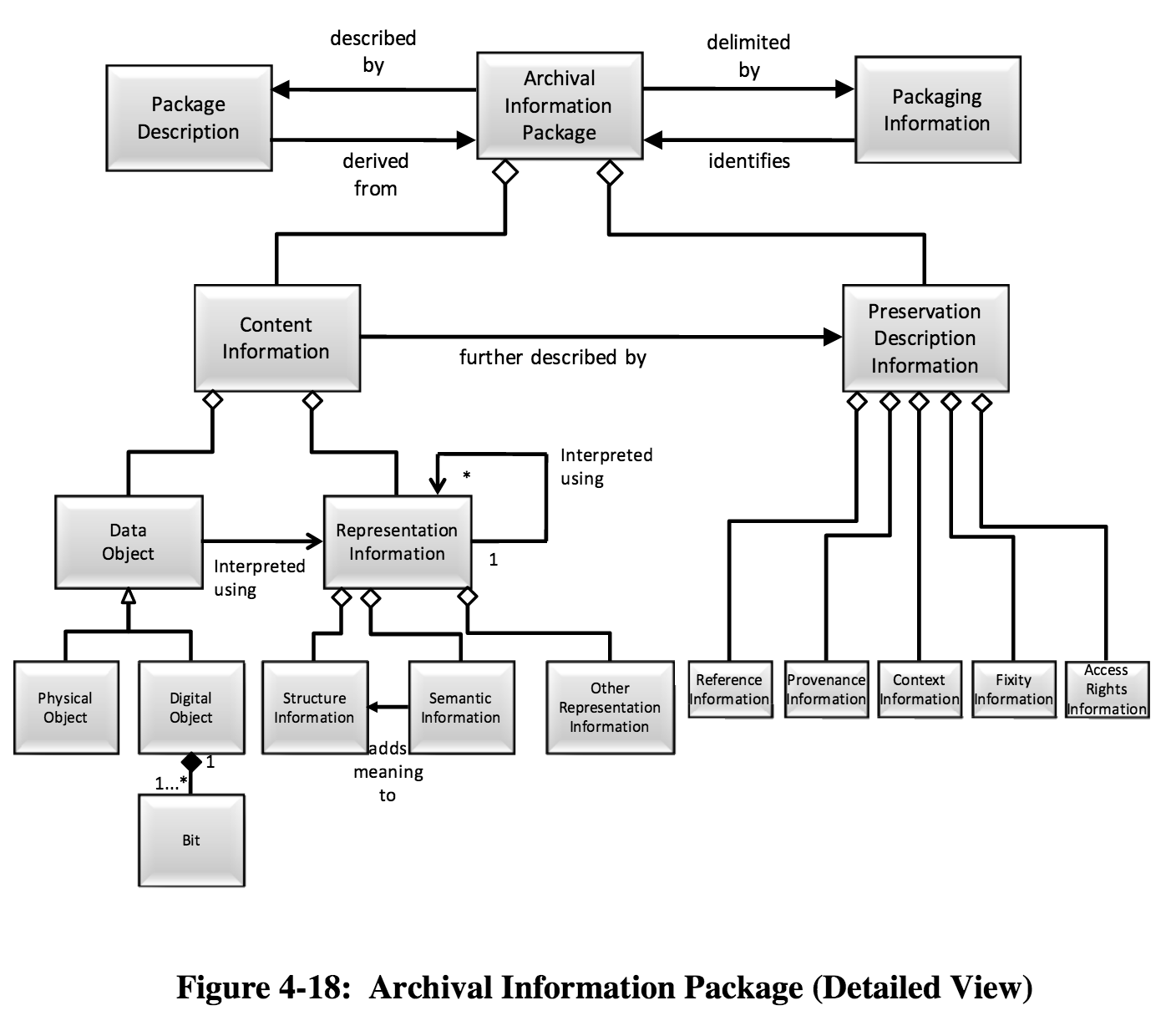
a potentially helpful but sort of confusing “conceptual” diagram of an AIP
A DIP on the other hand, is intended for the “consumer,” meaning that DIPs contain the “access copies” of content. Our DIPs consist of YouTube files, Mp3s for podcasts, a service copy for broadcast, and a collection of still images. But, we also include our DIPs in our AIP because we want to preserve not only our original file, but the derivatives and their corresponding metadata. Because AIPs are a conceptual model, it is difficult to figure out exactly what belongs in an AIP. According to the OAIS standards, “the AIP itself is an Information Object that is a container of other Information Objects. Within the AIP is the designated Information Object, and it is called the Content Information. Also within the AIP is an Information Object called the Preservation Description Information (PDI). The PDI contains additional information about the Content Information and is needed to make the Content Information meaningful for the indefinite Long Term.” (4-36 – 4-37). Are you wondering what an Information Object is? “The Information Object is composed of a Data Object that is either physical or digital, and the Representation Information that allows for the full interpretation of the data into meaningful information.” (4-20 – 4-21).
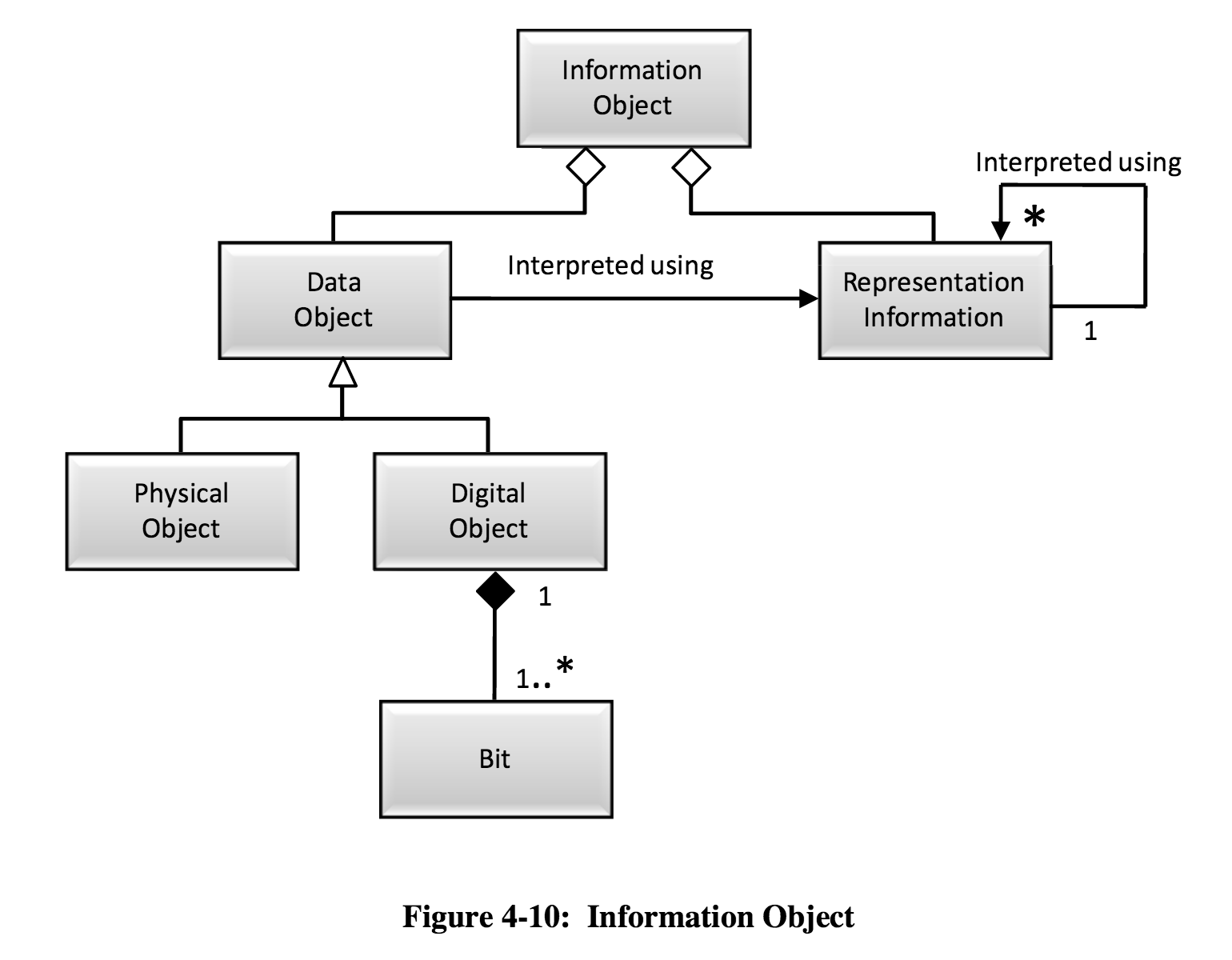
Here’s another OAIS diagram
To break this all down in the context of our archival workflows, and perhaps yours too, an Information Object is the video file and corresponding metadata that make possible the interpretation of the file. Our AIPs contain multiple Information Objects- our original preservation master, the service copy, access copies, and their metadata. Because OAIS provides a framework, and the AIP is a conceptual model, AIPs probably look really different across collections, which makes sense given different institutional needs. Here’s the structure of our AIPs using a command line tool called tree (which I’ll discuss more in the following section):
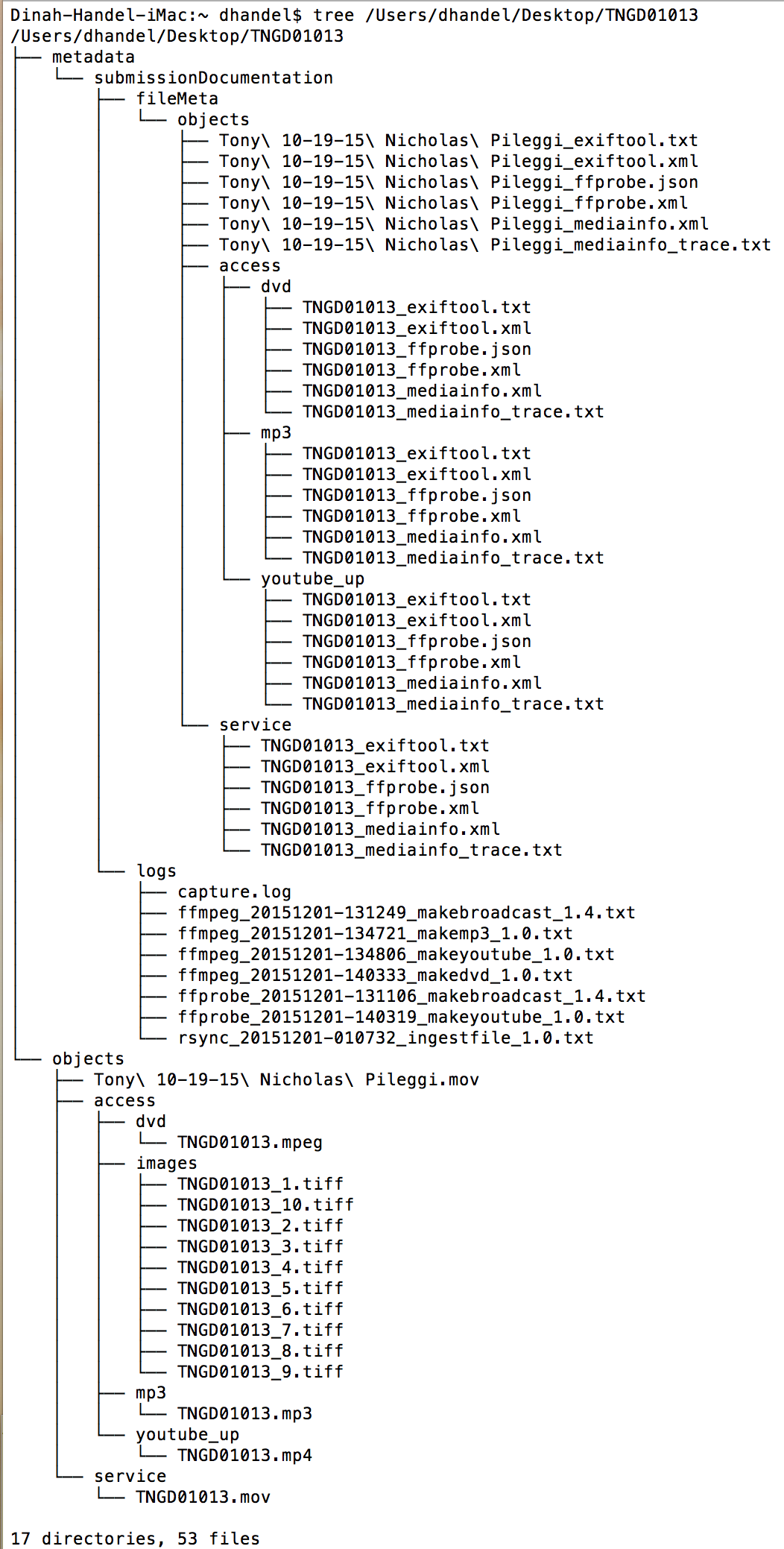
The structure of a CUNY TV Archival Information Package using the command line tool tree
Documenting and Validating AIPs
Let's go AIPshit. pic.twitter.com/5a8buSYHiI
— tvc15 (he/him) (@tvc15brian) December 2, 2015
In preparation for our data migration, we need to be able to pull all of our AIPs (approximately 1 petabyte of data, or 950,000 files) off our long term storage (LTO), perform fixity checks, and validate that the structure and contents of an AIP contain what we’ve defined they should. Specifically, we’ve been working to develop some kind of tool that can map out the directory structure of an AIP, and then validate its contents against a set of rules. At CUNY TV, we’re concerned about the change of internal AIP specification over time. For example, our digital preservation software, media micro-services, has evolved over the years. An AIP from 3 years ago won’t be the same as one created this week. In theory, this would be the case at other institutions as well, even with the use of digital preservation software like archivematica or preservica, as that software has changed over time.
If we accept that the contents and structure of an AIP might change over time, shouldn’t we be concerned about setting up institution-based parameters for what the AIP should look like? We’re not saying that an AIP specification has to be the same across all institutions, because that would be impossible given the plethora of digital content types, but that there should be a standardized way to document and verify the contents of an AIP. At CUNY TV, we also want to make sure that the files within the AIP are what they should be, for example, that they adhere to specific codecs and other encoding criteria. Do you share these concerns about documenting and verifying the contents of your AIPs?
Presently, we’re working on a solution that involves two scripts, maketree and verifytree. maketree uses a tool called tree, which you saw in the previous section, and creates an XML document that shows the structure and contents of our AIPs. With tree, we’re also able to show the date each file was last modified and its size. Then, verifytree uses xpath statements and xmlstarlet to run the XML document through a series of tests about the structure and contents of an AIP. If there are any discrepancies, verifytree spits them out into the terminal window. These processes are just the beginning though, as we’ll want to implement other forms of validation testing as well.
Still to come
One thing we want to be sure to test, as I mentioned earlier, is the file itself. We want to ensure that each of our access, service, and preservation master files adhere to a standard. Some of the AIPs we’ll be looking at are from 3 or 4 years ago, when we didn’t have the same workflow or internal standards that we do now. Our current thought is to use MediaInfo as a way of testing that a file adheres to specified requirements. We use MediaInfo to create metadata about files at their time of creation, and the output of that is an XML file. Similar to verifytree, we’d use Xpath statements again to test against a set of rules about the encoding of the file.
Another idea we’ve been considering is putting all of this metadata into a METS document and using something like METS Schematron to validate the contents and structure of the package. My mentor, Dave Rice, has been working on this aspect. What Dave has done thus far is take the output of the tree.xml file and the output of MediaInfo for master, service, and access copies, into a METS file. The process can be seen in makemets, on GitHub. This script isn’t completed yet, but is the beginnings of a way to represent the structure and contents of a package using METS. One issue that we’re having is implementing Premis events, in particular for files that do not have a corresponding MediaInfo file.
Finally, another aspect of this workflow to consider is how to log which packages do not validate, and automate a way to make sure they are reprocessed to the present AIP standard if needed. If we want to validate 1,000 packages at a time, or even 10 times that, ideally we wouldn’t just want all of that information to output into the terminal window. Some possible solutions would be to set up a system where if a package fails a test, we would log why it failed somewhere, and automatically move it to a place where it could be reprocessed OR reprocess it immediately once we know it failed.
Concluding thoughts

You may have noticed that there’s a lot of questions posed in this document. That’s because we’re genuinely curious how other organizations are looking at or handling these same problems, if at all. I really encourage discussion in the comments, on twitter, or feel free to email me at dinah [at] cuny.tv. There’s no AIP-shaming, and this is a safe-AIP-space. Thanks for reading, and I hope you’ll be in touch!
==========================
*Dave
[1] I grabbed this concept of an “active AIP” from page 8 the OAIS-YES docs, written at the AMIA/DLF Hack Day in November.
Really interesting blog post! I quite agree that a universal AIP specification is unrealistic (and probably undesirable). Instead what we aim for with the Archivematica project is for the AIPs to be self-describing and system independent so that they can be easily understood by other systems. We do this in two main ways: by using the bagit specification to package them, and by describing their content in METS files. The inside of an Archivematica AIP has a METS file describing the contents of the AIP, but the “outside” has a METS file too, called an AIP pointer file, which would be the useful thing for understanding the AIP as a whole by another system in the future.
Due to a project that we’re working on right now, we’re considering alternative ways of storing the AIP, so that each bitstream does not have to be packaged together necessarily. The AIP pointer files will be crucial in this project to make sure AIPs can be reconstituted if their parts are stored apart (like putting humpty dumpty back together!)
We’re going to be adding more information about these developments to this wiki page soon: https://wiki.archivematica.org/Improvements/AIP_Packaging
Thanks for reading and commenting, Sarah! We have appreciated archivematica’s openness around this issue, and generally. I’ll be sure to check back to the AIP Packaging wiki for developments. Making AIPs self-describing is a very useful concept, and I think that is what we’d like to aim for too. The question is what tools are best to do so? METS certainly is one option that we are exploring.
Hi Sarah,
I understand that to some extent an AIP can be self-describing, but there are some rules implied. For instance with Archivematica AIPs, the METS document is placed in the same relative position within the AIPs, so it’s easy to get to it. Since the METS is used for some many tasks, it would be far more challenging to manage if the METS may or may not exist in an AIPs in an unknown place with an unknown name.
I see with Archivematica the AIPs are highly consistent with the METS, the metadata directory, and the objects directory all in precise relative locations within the AIP. There is a wiki page that describes this at https://wiki.archivematica.org/AIP_structure. And this documentation (and/or the machine-readable version of this) is exactly what the blog post is talking about.
Active AIPs sound like situations where your AIP is your DIP as well. That doesn’t appear to be precluded by the OAIS model. Also I’ve always assumed the “consumer” in OAIS could be another system or process and that you may have multiple DIPs for different consumers, e.g. one for rebroadcast, one for web streaming etc. I haven’t had any reason to question that assumption so I hope it might be a useful one to share/get feedback on.
Regarding the AIP documentation: When we evaluated the commercial and open source solutions when selecting a digital preservation system recently, a key consideration we had was whether they had robust exist strategies. The availability of AIP documentation was a large component of that question and we were very happy with the answers from the product vendors/support teams.
I personally don’t see a great need for standardizing AIP structure documentation as AIPs are so rarely shared outside of an OAIS. The only use case I’ve come across so far (thanks @prwheatley is when an OAIS fails catastrophically and someone has to take ownership and control of the AIPs without being able to process DIPs out of them. In all other cases it seems that either DIPs can be created for external use or the processes applied to the AIPs can be managed using whatever AIP documentation you have for internal use.
On the other hand, having a standard DIP structure for use for migrating between OAISs and/or when moving to a new digital preservation system would be useful I think, and could also form an AIP structure if that was useful in a particular context.
Hi Euan,
Thanks for your comment! I’m hoping to get clarification on one aspect of your comments. When we migrate our AIPs from LTO 5 to LT), are we migrating AIPs or DIPs? We think we are migrating the AIP, from one LTO tape to another. But do you consider something a DIP once it begins the processing of moving from one place to another? I hope that question makes sense, I just want to try and understand the distinction you make between an AIP and a DIP, because I don’t think we have the same understanding. I appreciate the discussion!
Dinah
@Euanc
Although AIPs are so rarely shared outside of an OAIS, I do see a significant need to have a method to define and validate AIPS for the time that they do exist within a system. As an analogy I work with several XML specifications such as PBCore, FFprobe, PCMP, BXF, and METS. All of these have XML Schema Documents that provide a documentation of the structure and a machine-readable way to validate the expressions of those XML formats. Having the XML Schema allows us to catch issues very early rather than work to sustain malformed data that should get more immediate attention and repair.
For AIPs we have local rules on how the AIP should be structured and what shall be contained, but I would like a method (either local or shared with other OAIS practitioners) to turn these rules from oral-history into a machine-readable tests (as possible with XML Schemas). Without this we are challenged to document versioning of our AIP implementation or to have sufficient validation methods to apply when assessing the AIPs within a system. We can certainly test the checksums of the AIP but want to have a method to express rules such as: if the preservation master is video then the service copy must use one of two allowed video stream types, or that the service copy must adhere to a fixed frame rate and size, or that if the content is identified in a certain way than a certain type of access file must exist within the AIP, or that filenames shall not contain certain characters, or that NO .DS_Store files exist in the AIPs.
For now we can express these rules and test against them by verifying that the METS accurately represents the AIP, ensuring that the METS contains sufficient data to perform a test, and then using xpath tests against the METS. But still even to identify where in the AIP is the METS we need some expressed logic to do so.
Perhaps we are coming to a unique conclusion. And perhaps it may be that the majority of other OAIS practitioners see no priority in having a manner to define and/or validate local rules for AIPs within an OAIS system. However I suspect that other OAIS practitioners may have come to similar conclusions.
Two more things to add that I missed.
Great post thanks! It made me think to update my feedback on the OAIS wiki here.
Also, the last paragraph in my last comment should probably have said “having a standard DIP documentation structure for use for migrating…..” But that makes me wonder whether DIP standardization should be a bigger focus for so so many reasons (open access etc).
Thanks for the replies Dinah and David. I’m really enjoying the conversation.
Dinah:
I assume they are still AIPs if they are fully internal to the OAIS.
That kind of “migration” is a movement of files which you can manage through whatever process you want according to the OAIS. It would fall under the data management function I assume (actually on reference to the OAIS it looks like it’s the “archival storage” function that does most of that).
David:
Yep. All of what you said makes sense to me. I guess my point is just that each ‘off-the-shelf’ digital preservation system that exists currently, has this documentation already (you pointed out Archivematica’s great publically available documentation for example), and I don’t (yet -still open to convincing-) see the need to standardize across the different systems as all the use-cases (besides the one I mentioned that is rare) are internal to each system. Its definitely necessary documentation but standardizing the documentation structure is not necessarily necessary, in my opinion.
I’d also add that some of the DP systems use this documentation to manage and validate migration between storage systems (the kind of thing you are trying to do) and to manage regular validation across storage tiers, amongst other useful processes it’s used to manage/validate. So I see the need for the documentation, for sure, but it’s the standardization of the documentation structure across DPSs that I’m not convinced about.