Stanford University Web Archiving Service Manager Nicholas Taylor took to the podium about halfway through the sixth annual Archive-It partners meeting in Montgomery, AL, to unpack key findings of the National Digital Stewardship Alliance’s 2013 survey of web archiving in the United States.

Nicholas Taylor has a posse. Photo by Scott Reed, Archive-It.
Those survey results were recently very well summarized by co-author and Library of Congress web archiving team leader Abbie Grotke over at The Signal, and even a little bit further on our little blog, but Taylor also keyed in on one important finding that had been all but lost upon me until this day-long meeting of the minds: Archive-It, he demonstrated, has quickly become the American web archivists’ true community of practice. In just a few short years, membership in the Internet Archive’s browser-based software service has expanded to include more web archivists than any professional affiliation, including the national organization of digital preservation institutions that commissioned this study.

Percentage of NDSA Web Archiving survey respondents by affiliation. Graph by Karl-Rainer Blumenthal.
This leads us to two important conclusions: 1) that the shoestring-budgeted service deserves significantly greater investment, and 2) that beyond a day to pick nits with vendor representatives, its annual meeting actually provides partners with their most inclusive opportunity to articulate and debate the state of web archiving in America.
From that context, I left AIT14 with a vision of web archiving as moving in two divergent, but not necessarily competing, directions: one extensive, nimble, and “big data”-driven; the other intensive, rigorous, and devoted to preserving precious artifacts. You can see the themes emerge throughout my bafflingly comprehensive notes on all presentations (really, you might want to get a snack), but I’ll break them down here in the meantime.
Representing the value of scaling up investment in Internet Archive’s technology suite, several partners introduced attendees to projects that bridge the data service gap with researchers in need of statewide and national coverage rather than the patchwork of individual websites accessible through the general Wayback Machine. Take just for instance the Integrated Digital Event Archive and Library (IDEAL) project presented by Virginia Tech CTRnet Research Group’s Mohamed Farag. At the center of IDEAL’s research and development is the Event Focused Crawler (EFC), a curator-modeled and then self-refining web crawler that captures websites central to events that spontaneously combust on social media for long-term preservation and ultimate linguistic or otherwise large-scale thematic analysis. Modest enough in concept, even VT’s most foundational technical efforts require large and continued investment by the National Science Foundation.
Internet Archive clearly recognizes the research value of the kind of data stores that VT’s and others’ projects bequeath. Culminating the day’s presentations, program manager Jefferson Bailey and engineer Vanay Goel unveiled Archive-It Research Services, Internet Archive’s own pilot effort to provide technologist researchers with tools designed especially for the longitudinal, graphical, and otherwise visually compelling analysis of Archive-It partners’ curated web collections. Scaling the pilot up to full-scale launch in January hinges upon the viability of file formats developed by Internet Archive engineers to circumvent the need for the kind of massive computational infrastructure that their organization enjoys, but that most individual researchers lack.
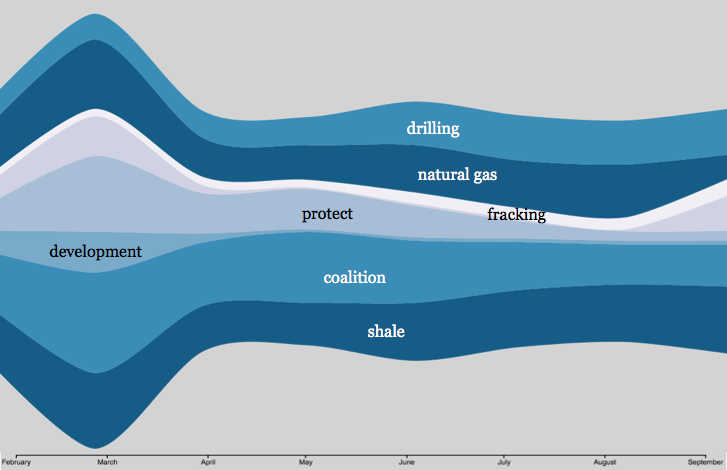
Graph of metatext frequency in the Hydraulic Fracturing in New York State Web Archive, Feb-Sept 2014, by Archive-It Researcher Services.
Of course all American web archivists–or at least those of us working in education and government–share a dirty little secret: that our big data bucket has a hole in it. I’ve spent the better part of my first phase of NDSR work, in fact, inventorying known issues and strategies to mitigate problems of capturing and rendering web content. It’s tempting to overlook these myriad gaps when you still have huge stores of web-native data to analyze, but practically impossible when your charge is to completely capture and accurately render a single, discrete website. NYU music librarian Kent Underwood demonstrated the need for this extremely careful approach. He reminded attendees that Baroque composer Johann Sebastian Bach’s long marginalized scores and manuscripts required stewardship to future generations that could appreciate them. Without rapid and significant improvement to the tools that we use to capture time-based web media like streaming audio, video, and Flash-based applications, the records of emergent young artists in NYU’s Archive of Contemporary Composers’ Websites will not live so long.
You don’t have to be an art librarian to see the dramatic downstream effects of this problem, but it certainly helps! Susan Roeper and Penny Baker of the Sterling & Francine Clark Art Institute Library, for instance, demonstrated how their institution’s long history of collecting catalogues and ephemera from the Venice Biennale required them to quickly become experts in web archiving’s most commonly problematic content types. Their web archive, in turn, reflects less the kind of documentation that could previously have been feverishly snatched up and fit into a colleague’s briefcase, rather the equally fragile born-digital and frequently interactive kinds of media that increasingly define the way that we design for the modern web.
To me, though, the finest point was put on this challenge by Heather Slania, Library Director at the National Museum of Women in the Arts. Like many of her colleagues in universities and government agencies, Slania was introduced to web archiving as a means to preserve her institution’s online presence ahead of a major redesign, but she soon applied it to her museum’s broader collecting mission. Archiving internet art, she explained, offered her the opportunity to preserve the work of women artists traditionally marginalized when not outright omitted from the art historical canon and from the scopes of landmark collecting institutions. Without advancing Archive-It’s capacity to fully capture and accurately replay them, these always imaginative and often subversive uses of the web as an artistic medium are destined to live on only in hints and rumors. Slania has already reduced her original collection of 36 sites down to 29 due to sites going completely offline, and as of 2014 she estimates that half of this collection experiences moderate to complete loss of content in an archival environment.

Susan Roeper (left) and Heather Slania (right) in front of two very perishable records: a salami and an internet artwork. Photos by Scott Reed, Archive-It.
My host, NYARC, is doing its part to ensure that the integrity of these sites remains a priority while web archiving expands into larger scale data services territory. In scarily few weeks I will publish my draft procedures for assuring the quality of specialist art historical resources archived from the web. In the meantime, we took home AIT14’s prize for “best documented tech support questions,” which I suppose means that I must be doing something right…

How could I not pick the Neapolitan astronaut ice cream out of the prize bin? Photo by Karl-Rainer Blumenthal.
In all seriousness though, the opportunity for a narrowly and preservation focused operation to refine technology that is increasingly applied at such wider scales and iterative phases of research makes me optimistic that the parallel courses of web archiving described above will continue to inform and improve one another. Archive-It brought us all together under one roof, after all, and everyone seems to feel at home here.